Łączna kwota:
plus VAT.
Sztuczna inteligencja nie potrzebuje superkomputerów, a firmy już gromadzą dane, z których można uzyskać cenne wnioski za pomocą modelu AI. Nasze centrum kompetencyjne AI oferuje wiele korzyści przy wdrażaniu AI w Twoim systemie wbudowanym:
- Wewnętrzny analityk danych jako bezpośredni kontakt
- Zestawy AI do eksploracji danych
- Szkolenia AI + seminaria online
- Zwinny zespół ds. Rozwoju oprogramowania i sprzętu
- Analiza + porady dotyczące rozwiązania
Centrum kompetencji AI _ Nasze specjalistyczne know-how dla Twojego rozwoju
Z modelu
do osadzonego
Aplikacja AI
Aby przybliżyć naszym klientom możliwości rozwiązań AI i zaoferować jak najlepsze wsparcie z jednego źródła, utworzyliśmy centrum kompetencyjne dla AI. Zespół wokół naszego wewnętrznego analityka danych Dr. Jan Werth z wieloletnim doświadczeniem w wykorzystaniu sztucznej inteligencji pokazuje możliwości uczenia maszynowego i znajduje odpowiednie rozwiązanie dla Twojego projektu. Zgodnie z własnymi życzeniami i kompetencjami, sprawnie uzupełniamy zespół o ekspertów w dziedzinie chmury i bezpieczeństwa, a także programistów i sprzętowych.
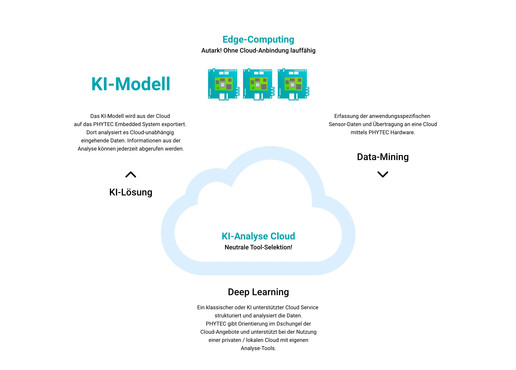
Chmura obliczeniowa
Przetwarzanie w chmurze opisuje przeniesienie mocy obliczeniowej do chmury. Wyniki można rozpowszechniać bezpośrednio online.
Obliczenia EDGE
W przypadku przetwarzania brzegowego dane są przetwarzane w miejscu ich pochodzenia. Modele do przetwarzania można tworzyć za pośrednictwem przetwarzania w chmurze, ale działają one lokalnie. Połączenie w chmurze jest możliwe, ale nie jest absolutnie konieczne. Przetwarzanie brzegowe nadaje się zatem również do zastosowań krytycznych dla bezpieczeństwa.
Masz pytania dotyczące wykorzystania sztucznej inteligencji
czy potrzebujesz wsparcia przy swoim projekcie?
Centrum Kompetencji PHYTEC AI z przyjemnością Ci pomoże.
AI, Machine & Deep Learning _ Jest już od dawna. Dlaczego teraz? Co się zmieniło?
Podstawowe idee i algorytmy uczenia maszynowego są znane od dawna. Jednak w ciągu ostatnich 50 lat zmieniły się decydujące warunki ramowe, które obecnie prowadzą do szybkiego sukcesu SI:
- Zwiększona moc obliczeniowa
- Liberalizacja mocy obliczeniowej poprzez przetwarzanie w chmurze
- Adaptacja mocy obliczeniowej
- Wykładniczy wzrost danych
- Niedrogie miejsce do przechowywania
- Łatwe w użyciu narzędzia analityczne typu open source
Zwiększona moc obliczeniowa umożliwia radzenie sobie z procesami obliczeniowymi wymagającymi dużych zasobów w rozsądnych czasach. Równie ważna jest liberalizacja mocy obliczeniowej, która umożliwia każdemu użytkownikowi opanowanie skomplikowanych modeli bez konieczności wcześniejszego konfigurowania i utrzymywania infrastruktury o wysokiej wydajności. Dziś pożyczamy moc obliczeniową - dokładnie tyle, ile potrzebujemy i tylko na niezbędny czas. Jednocześnie ilość danych, które mamy dostępne do uczenia nowoczesnych algorytmów, rośnie wykładniczo. Szacuje się, że 90% wszystkich danych zostało wygenerowanych w ciągu ostatnich dwóch lat. Od 2018 roku przekroczono dwa zettabajty danych. Oznacza to, że po 2018 roku rocznie będzie generowanych ponad dwa zettabajty danych. Ta eksplozja danych napędza sukces żądnych danych algorytmów, takich jak głębokie uczenie się. Ważne jest również, aby platformy open source, takie jak Phyton, zostały zoptymalizowane pod kątem uczenia maszynowego. Od 2015 roku, wraz z wprowadzeniem Keras i TensorFlow, głębokie uczenie się zostało również zintegrowane z Phythonem w sposób przyjazny dla użytkownika i bez licencji.

Te trzy terminy oznaczają podkategorie sztucznej inteligencji.
Nauczanie maszynowe
odnosi się do uczenia się na przykładach. Algorytm nie uczy się wszystkich przykładów na pamięć, ale poznaje podstawowe cechy przykładów, a następnie może je zastosować do niewidocznych danych.
głęboki Learning
jest podkategorią uczenia maszynowego i działa na podobnych zasadach. Zasadnicza różnica polega na niezależnym dostosowaniu parametrów w celu uzyskania optymalnych wyników. Dzięki głębokiemu uczeniu się można rozwiązać złożone pytania z wieloma nieliniowymi zależnościami.
Big Data
odnosi się do wykorzystywania dużych ilości danych, które ze względu na ich rozmiar nie mogą być przetwarzane w konwencjonalny sposób. Big data można analizować za pomocą uczenia maszynowego lub uczenia głębokiego.
Nic nie działa bez sprzętu _ Smarte Systemy wbudowane ze zintegrowanym uczeniem maszynowym
Gromadzenie, przechowywanie, strukturyzacja i analiza danych to wyzwania związane ze sztuczną inteligencją. Część sztucznej inteligencji wymagająca dużej mocy obliczeniowej polega na tworzeniu modelu. Jednocześnie potrzebny jest sprzęt, który rejestruje te dane, wstępnie je przetwarza, wysyła do komputera / serwera lub sam przetwarza.
Aby zapewnić optymalną funkcjonalność urządzenia brzegowego, sprzęt musi być wydajny i energooszczędny. PHYTEC łączy elementy konstrukcyjne z wieloletniego doświadczenia w dziedzinie rozwoju sprzętu i rozwoju jądra/oprogramowania z wiedzą ekspercką w dziedzinie analizy danych. Przejdź od razu do rozwoju sztucznej inteligencji dzięki naszym zestawom AI.

Ekspert AI Dr. Jan Werth _ na Embedded World 2020
Seminaria online _ Pomocna wbudowana wiedza wyjaśniona w skrócie w krótkich sesjach wideo

Podczas pouczających seminariów online z naszymi ekspertami i partnerami poinformujemy Cię o ekscytujących tematach z branży rozwiązań wbudowanych.
Otrzymasz bezpłatny wgląd w nowe rozwiązania sprzętowe i programowe oraz dowiesz się więcej o ofertach specjalnych.
Nasi wbudowani eksperci są do Twojej dyspozycji!
Zapewnij sobie osobistą wizytę konsultacyjną szybko, łatwo i bezpłatnie.
30 minut wyłącznie dla Ciebie i Twojego projektu!
Inne interesujące tematy: